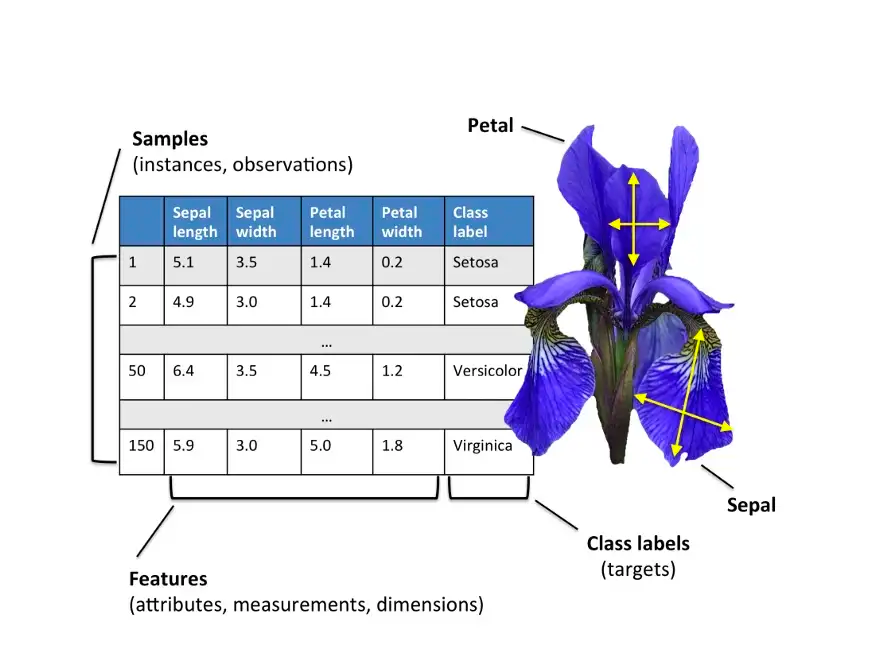
یک مثال سریع: مجموعه دادهی Iris
بیایید سریع ببینیم تحلیل دادهها و یادگیری ماشین چطور روی مجموعه دادههای واقعی کار میکنن. هدف اینجا اینه که پتانسیل پایتون و یادگیری ماشین رو روی برخی مسائل جالب نشون بدیم.
در این مثال خاص، هدف اینه که گونهی گل Iris رو بر اساس طول و عرض کاسبرگها و گلبرگها پیشبینی کنیم. اول، باید یه مدل بسازیم بر اساس مجموعه دادهای که اندازهگیریهای گلها و گونههای مربوط به اونها رو داره. بر اساس کدمون، کامپیوتر “از دادهها یاد میگیره” و الگوهایی از اون استخراج میکنه. بعد از این، چیزی که یاد گرفته رو روی یه مجموعه دادهی جدید اعمال میکنه. بیایید به کد نگاه کنیم:
مرحله 1: نصب و وارد کردن کتابخانهها
اولین کاری که باید انجام بدیم نصب و وارد کردن کتابخانههای لازم هست:
import pandas as pd from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split from sklearn.ensemble import RandomForestClassifier from sklearn.metrics import accuracy_score
مرحله 2: بارگیری دادهها
حالا مجموعه دادهی Iris رو بارگیری میکنیم:
# بارگیری مجموعه دادهی Iris iris = load_iris() data = pd.DataFrame(data=iris.data, columns=iris.feature_names) data['species'] = iris.target
مرحله 3: تقسیم دادهها به مجموعهی آموزشی و آزمایشی
برای ارزیابی عملکرد مدل، دادهها رو به دو بخش آموزشی و آزمایشی تقسیم میکنیم:
# تقسیم دادهها به مجموعههای آموزشی و آزمایشی X = data[iris.feature_names] y = data['species'] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
مرحله 4: ساخت و آموزش مدل
حالا یک مدل جنگل تصادفی (Random Forest) میسازیم و اون رو آموزش میدیم:
# ساخت و آموزش مدل جنگل تصادفی model = RandomForestClassifier(n_estimators=100, random_state=42) model.fit(X_train, y_train)
مرحله 5: پیشبینی و ارزیابی مدل
بعد از آموزش مدل، پیشبینیها رو روی مجموعهی آزمایشی انجام میدیم و دقت مدل رو ارزیابی میکنیم:
# پیشبینی روی مجموعهی آزمایشی
y_pred = model.predict(X_test)
# ارزیابی دقت مدل
accuracy = accuracy_score(y_test, y_pred)
print(f'DAccuracy: {accuracy * 100:.2f}%')
نتیجه
اگر همه چیز به درستی پیش بره، باید دقت مدل رو ببینیم که به احتمال زیاد بالاست، چون مجموعه دادهی Iris نسبتاً ساده و تمیزه.
توضیح مختصر کد
- بارگیری دادهها: ابتدا مجموعه دادهی Iris رو از کتابخانهی
sklearnبارگیری میکنیم و اون رو به یک DataFrame تبدیل میکنیم. - تقسیم دادهها: دادهها رو به دو بخش آموزشی (برای آموزش مدل) و آزمایشی (برای ارزیابی مدل) تقسیم میکنیم.
- ساخت و آموزش مدل: یک مدل جنگل تصادفی میسازیم و اون رو با استفاده از دادههای آموزشی آموزش میدیم.
- پیشبینی و ارزیابی: پیشبینیها رو روی مجموعهی آزمایشی انجام میدیم و دقت مدل رو محاسبه میکنیم.
این یک مثال ساده اما کاربردی از اینه که چطور میتونیم با استفاده از پایتون و یادگیری ماشین، مسائل جالب و واقعی رو حل کنیم و بینشهای ارزشمندی از دادهها استخراج کنیم.









